CSC 111: Intro to Computer Science through Programming
Homework 5
Due: Tuesday, Mar. 21 at 11:59pm on Moodle
Quiz 5
Please take the short Week 5 quiz on Moodle (also due by Tuesday night). This is to help me understand what areas need work, and also help you understand what concepts might need extra practice. It is not a large part of the overall homework grade. Just for the quiz part, do not discuss the questions with other students, TAs, etc. (Note: quiz usually posted Wednesday afternoon.)
Credit: thank you to Joe O'Rourke for this idea and for providing the code to capture the tweets
Analyzing a Twitter feed
For this homework we will be analyzing tweets. The Twitter capture was done during the middle of the Oscars on February 26, 2017. Many of the tweets are about the Oscars, although the capture was not specific to any one topic.The files we will be analyzing are:
tweets_26Feb2017_short.txt (1.5Mb)
tweets_26Feb2017.txt (22Mb)
Right-click to download the files, don't open them in your browser and copy over the data. I would recommend starting with the short file and make sure that everything is working on that file first before moving to the full set of tweets.
Here is an example of tweet in the first file:
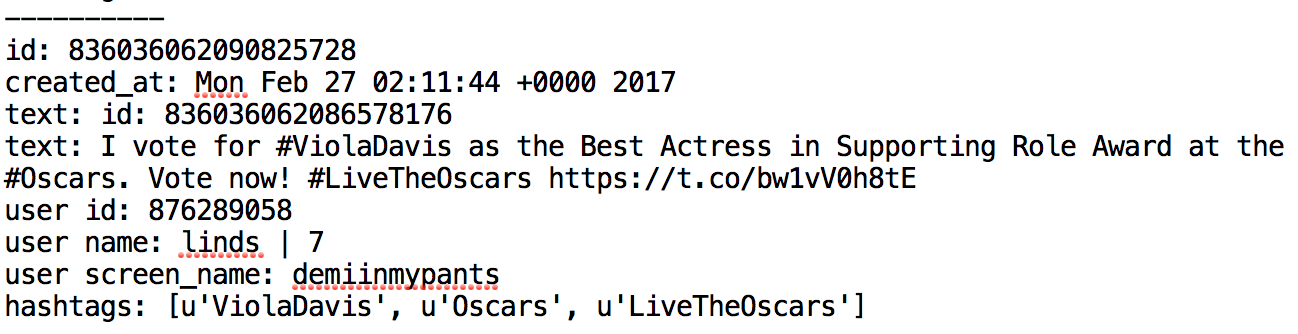
For this homework, create a file hw5.py with a main method, and compute the results described below. Exactly how you do this is up to you. You do not have to use helper functions, but if your main method becomes very long and meandering, consider encapsulating certain tasks into helper functions. As a general rule of thumb, your main method should be able to fit on one screen using a reasonably large font.
- Oscar in tweets
First compute the number of times the word "oscar" is seen inside a tweet (i.e. the "text:" field of a tweet). No need to use split(), the built-in string method count() should be enough. Your count should include upper and lowercase instances.
- Viola in tweets
Next compute the number of times the word "viola" is seen inside a tweet (Viola Davis won best actress in a supporting role, which was one of the most-tweeted events during this Twitter capture.) Again include both upper and lowercase instances.
- Oscar in hashtags
Repeat (1), but for the word "oscar" seen as part of a hashtag (i.e. the "hashtags:" field of a tweet).
- Viola in hashtags
Repeat (3), but for the word "viola" seen as part of a hashtag (i.e. the "hashtags:" field of a tweet).
- Unique hashtags
In this last part, create a list of all unique hashtags. First, before looping through each line of the file, create an empty list to store the hashtags. Then, whenever you encounter a string of hashtags, use eval to turn it into list as shown below (the "u" is for unicode):

Then consider each tweet in this mini-list of tweets. If you have it in your large list of all tweets, don't add it again. But if it is not in your large list of tweets, add it. Here is an example of how to check if a list contains a given element:

After creating this list of all unique hashtags, print out how many unique hashtags there are.

Repeat the process above for the large file. Save both of these final results as your transcript.
Extensions
Optional ideas to extend your code:(A) Instead of just printing the number of unique hashtags, also maintain another list that counts how many times each hashtag was used. Then use this list to find the most frequent hashtag (think about how to use the functions min/max/index).
(B) Choose a few more keywords of your own and print their counts as well. Or you could choose two words and see how often they appear together in the same tweet.
Transcript and Submit
Finally, create a transcript that demonstrates your code working on the short file and the long file (but nothing else, just the final output for these two files). Save this file as hw5_transcript.txt. Also make sure your code is commented, and that you have given some thought to the header, variable names, whitespace, readability, and efficiency. Style will be a larger part of the evaluation for this homework.
TO SUBMIT ON MOODLE:
- hw5.py
- hw5_transcript.txt